

Liquid Neural Networks: The Architecture That Adapts After Training & Why AMD Bet $250M on It
Most AI models freeze after training. Liquid neural networks keep adjusting in real time, and the startup commercializing them just became a $2 billion unicorn.


What Liquid Neural Networks Actually Are
A standard AI model like GPT or Gemini learns during training and then freezes. The parameters are fixed. When you send it a prompt, the model processes your input through the same static weights every time. If the world changes or the data shifts, the model does not adapt. You retrain it, which costs millions of dollars and months of compute.
Liquid neural networks work differently. Developed at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) by Ramin Hasani, Mathias Lechner, Alexander Amini, and Daniela Rus, liquid networks use continuous-time dynamics where the model’s parameters adjust based on the input it receives, even after training is complete. In plain language: the model rewires itself as new data comes in.
The original paper on Liquid Time-Constant (LTC) networks was published in 2021. The key insight was borrowed from neuroscience. The neurons in a C. elegans worm, which has only 302 neurons, can produce remarkably complex behavior because the connections between neurons are dynamic, not fixed. The time constants governing how quickly each neuron responds can change based on incoming signals. Hasani and his co-authors built that principle into an artificial neural network: instead of fixed-weight connections, the network uses ordinary differential equations (ODEs) to model how each neuron’s state evolves over continuous time.
A follow-up paper in Nature Machine Intelligence in 2022 introduced closed-form continuous-time (CfC) networks, which solved the computational overhead problem of the original liquid networks. The original LTC networks required numerically solving differential equations at each step, which was slow. CfC networks found a mathematical shortcut: a closed-form solution that achieves the same adaptive behavior without the computational cost of solving ODEs at every inference step.
The result is a model that is small, interpretable, and adaptive. Where a large language model might need billions of parameters, a liquid network can achieve strong performance on time-series and sequential data tasks with thousands to millions of parameters. A liquid network with 19 neurons was able to steer a self-driving car. You can look inside a liquid network and understand why it made a specific decision, trace which neurons responded to which inputs, and see how the time constants shifted. That kind of interpretability is nearly impossible with transformer-based models that have billions of opaque parameters.
How Liquid Networks Compare to Transformers
The technical differences between liquid neural networks and transformers are fundamental, not incremental.
Transformers process input in parallel through self-attention, which compares every token to every other token. This is powerful for language because it captures long-range dependencies, but it scales quadratically with sequence length. A 10x longer input requires 100x more compute for the attention step. Transformers are also static after training: the weights do not change regardless of what input they see.
Liquid neural networks process input sequentially through continuous-time dynamics. Each neuron’s behavior is governed by a differential equation whose parameters can shift based on the current input. This makes them naturally suited for time-series data, sensor streams, and any task where the data arrives in a sequence and the underlying conditions may change. The trade-off is that liquid networks do not handle the kind of broad, parallel language processing that transformers excel at.
State space models like Mamba (developed by Albert Gu and Tri Dao) are a third approach. Mamba offers linear-time sequence processing, compared to transformers’ quadratic cost, by using structured state spaces to model sequences efficiently. Mamba is static after training, like a transformer, but much more computationally efficient for long sequences.
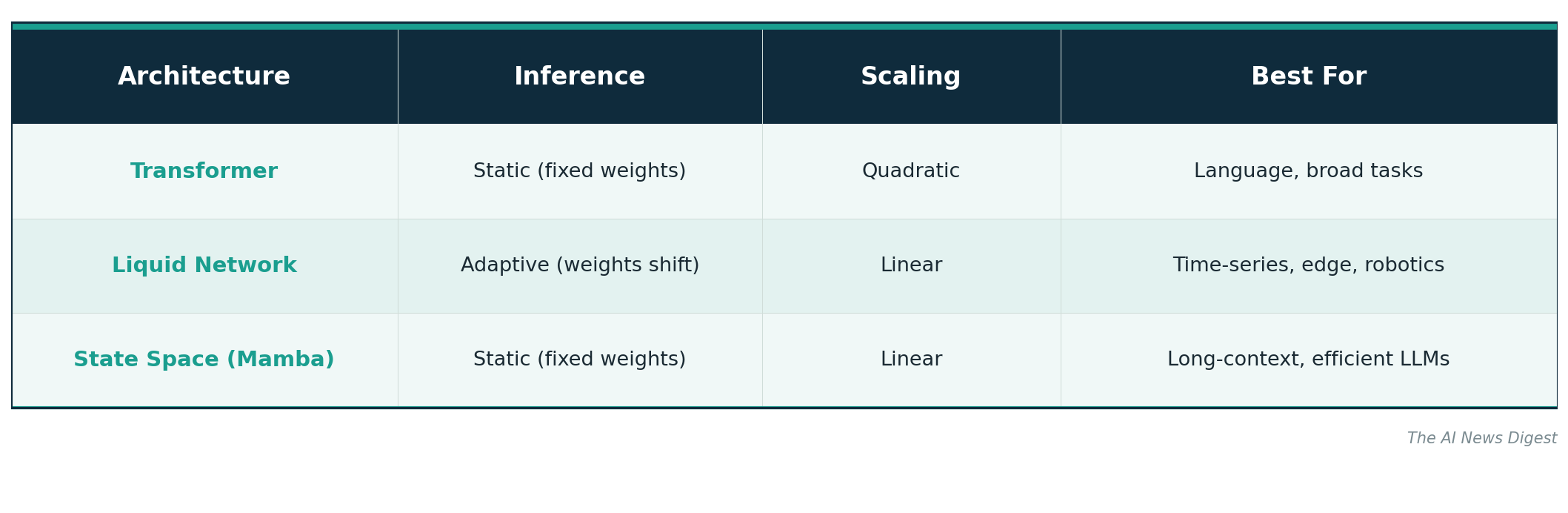
The key differentiator for liquid networks is inference-time adaptation. The model changes its behavior based on input without retraining. For applications like autonomous systems, where conditions shift constantly, this is a structural advantage that neither transformers nor state space models offer.
Liquid AI: From MIT Lab to $2 Billion Unicorn
The four MIT CSAIL researchers founded Liquid AI in 2023 to commercialize their research. The company emerged from stealth in December 2023 with $46.6 million in seed funding led by OSS Capital and PagsGroup (the family office of Stephen Pagliuca). Investors included Breyer Capital, Naval Ravikant (AngelList co-founder), Tobias Lutke (Shopify co-founder), David Siegel (Two Sigma co-founder), Chris Prucha (Notion co-founder), Bob Young (Red Hat co-founder), Samsung Next, and Bold Capital Partners (Peter Diamandis).
The investor list is notable for its breadth. These are not just AI VCs. They are operators who have built platform-scale businesses and understand infrastructure economics. Tobias Lutke later became a customer through the Shopify partnership.
A year later, in December 2024, AMD Ventures led a $250 million Series A, valuing Liquid AI at $2 billion. AMD’s investment was strategic on both sides. Liquid AI committed to optimizing its models for AMD’s GPUs, CPUs, and AI accelerators. AMD got a foothold in the efficient-AI market where its hardware can compete with Nvidia on price-performance. Nvidia dominates the training of massive models, but smaller, more efficient models play to AMD’s strengths.
In total, Liquid AI has raised $297 million across two rounds. That is a fraction of what the foundation model labs have raised (OpenAI at $58 billion, Anthropic at $14 billion), but Liquid AI is not competing on the same axis. They are not trying to build the biggest model. They are trying to build the most efficient one.
The Models: From Cloud to Smartphone
Liquid AI has shipped a rapid succession of models and products since early 2025, each targeting a different point on the compute spectrum.
LFM-7B launched in January 2025 as a 7 billion parameter Liquid Foundation Model. At its size class, it was best-in-class for local deployment and latency-constrained tasks, supporting multiple languages. Unlike transformer models of similar size (Llama 3.2 7B, Mistral 7B), LFM-7B uses Liquid AI’s non-transformer architecture, which means lower memory usage and faster inference for the same parameter count. The architecture combines elements of attention, convolutions, and recurrence in a hybrid design rather than relying purely on self-attention.
Hyena Edge arrived in April 2025, designed specifically for smartphones and edge devices. This is where Liquid AI’s approach gets genuinely differentiated. Hyena Edge was designed using STAR (Synthesis of Tailored Architectures), an evolutionary framework that uses evolutionary algorithms to automatically design model architectures. STAR encodes each model design as a numeric “genome” and evolves these genomes over successive generations, selecting top performers, recombining them, and refining designs to meet specific goals like inference speed and memory efficiency on target hardware.
Starting with 16 candidate architectures and running 24 generations of evolutionary iterations, STAR produced Hyena Edge. The model replaces two-thirds of traditional grouped-query attention operators with gated convolutions from the Hyena family. Results on a Samsung Galaxy S24 Ultra: 30% lower latency than Transformer++ baselines at longer sequence lengths, 90% smaller cache size compared to transformers, and 37% cache reduction compared to hybrid models, all while matching or exceeding quality benchmarks. In 7 out of 8 tests, the STAR-evolved architectures outperformed both Transformer++ and hybrid models while reducing parameter counts by up to 13%.
Liquid Nanos debuted in September 2025 as ultra-small, task-specific models designed to run directly on iOS and Android devices. Rather than one large model handling everything, Nanos let an application outsource specific tasks to tiny, energy-efficient models running locally. They are available through LEAP (Liquid Edge AI Platform), with Apollo as a companion app for testing small language models directly on your phone.
In January 2026, Liquid AI announced new models that it says beat open-source competitors from Meta, Alibaba, and others at comparable sizes.
The Partnerships Tell the Story
The partnerships Liquid AI has signed reveal where efficient, adaptive AI has the strongest product-market fit.
Shopify signed a multi-year deal in November 2025 to license and deploy Liquid AI’s LFMs across quality-sensitive commerce workflows. The first production deployment is a sub-20 millisecond text model that enhances search. Shopify and Liquid co-developed a generative recommender system with a novel HSTU architecture. When your Shopify search returns relevant products in under 20 milliseconds, that is not a 70 billion parameter model running in a distant data center. It is a small, fast, specialized model running close to the user.
G42, the Abu Dhabi-based technology group, partnered with Liquid AIin June 2025 to deliver private, local AI solutions for enterprises. The partnership focuses on creating, training, and commercializing generative AI solutions powered by Liquid Foundation Models. For Middle Eastern enterprises with strict data sovereignty requirements, running AI locally rather than routing through U.S. cloud providers is not a nice-to-have. It is a regulatory necessity.
Brilliant Labs integrated Liquid AI into its Halo smart glasses in September 2025. Running an LLM on smart glasses means operating within severe power and compute constraints. A model that is both small and adaptive, one that can adjust its behavior based on what the wearer is seeing and doing, fits a use case that transformers cannot serve efficiently.
Alef Education partnered with Liquid AI in August 2025 to advance AI in education. AMD is optimizing its hardware stack for Liquid Foundation Models. Each partnership reinforces the same thesis: there is a large and growing market for AI that runs on the device, not in the cloud.
Why This Matters for the AI Industry
The dominant narrative in AI is that bigger models are better models. Meta guided 2026 capex to $115 billion to $135 billion, essentially all of its free cash flow. Microsoft has a $625 billion demand backlog for Azure AI compute. The infrastructure race is consuming hundreds of billions. The entire industry assumes that scale is the path to capability.
Liquid AI is building for a different future. Their thesis is that for many real-world applications, you do not need a trillion-parameter model. A drone navigating a warehouse does not need GPT-5. A smart glass displaying contextual information does not need Gemini. A commerce search engine returning results in under 20 milliseconds does not need a model that costs $3 per million tokens. These use cases need fast, efficient, adaptive AI that runs where the data is generated.
If edge AI grows as projected, with Gartner estimating over 75% of enterprise data will be processed outside traditional data centers by 2027, Liquid AI’s bet looks well-timed. The AI industry is pouring hundreds of billions into cloud infrastructure for a world where everything runs in the data center. Liquid AI is building for the world where the compute happens on the device in your hand.
The company’s challenge is scaling its approach beyond niches. Their models are not designed for the kind of broad, open-ended conversation that GPT or Gemini target. But Liquid AI has been clear about this: they are building “efficient general-purpose AI at every scale.” The $2 billion valuation and AMD’s backing suggest the market believes that not all AI needs to be big to be valuable.
Frequently Asked Questions
What are liquid neural networks?
Liquid neural networks (LNNs) are a continuous-time neural network architecture introduced by Ramin Hasani and collaborators at MIT in 2021 (Liquid Time-Constant Networks paper). The architecture uses time-continuous differential equations as the activation function rather than the discrete time steps used by conventional neural networks. The result is an architecture that adapts its dynamics over time, handles continuous sensor data efficiently, and uses far fewer parameters than transformers for sequential tasks. The original work demonstrated that 19-neuron LNNs could match larger conventional networks on autonomous driving control tasks.
Liquid neural networks architecture: how does it work?
The liquid neural network architecture replaces conventional discrete activation functions with continuous-time differential equations. Each neuron’s state evolves over time according to a learned time-constant parameter, which means the network’s effective dynamics adapt to the input signal. This produces three notable properties: parameter efficiency (LNNs typically need 10-100x fewer parameters than transformers for the same task), interpretability (the continuous-time dynamics are mathematically tractable), and robustness to distribution shift (the adaptive time constants handle inputs the network was not trained on). The architecture is most useful for sequential tasks like control, robotics, and time-series prediction.
Liquid time-constant networks Hasani 2021 equation: what is it?
The Hasani 2021 Liquid Time-Constant Networks paper introduced the core LNN equation: dx/dt = -x/τ(x,I,t,θ) + f(x,I,t,θ) ⊙ A, where x is the neuron state, I is input, τ is the learned time constant (which itself depends on state and input, making it adaptive), f is the nonlinear activation, A is a learned bias, and θ is the parameter set. The equation is a continuous-time ordinary differential equation solved during forward passes via numerical integration. The “liquid” name comes from the time constant changing dynamically with input, making the network’s effective dynamics fluid rather than fixed.
Liquid neural networks vs Mamba and RWKV in 2026?
Liquid neural networks, Mamba (state space models), and RWKV (linear attention) are three alternatives to the standard transformer architecture, each with different tradeoffs. LNNs win on parameter efficiency and interpretability for low-dimensional control tasks but have not scaled to language modeling at the largest sizes. Mamba scales to billions of parameters and matches transformer language modeling performance with linear-time inference, making it the strongest transformer alternative for LLMs in 2026. RWKV combines RNN-style efficiency with transformer-level performance and is widely deployed in mid-scale language models. For language modeling at scale: Mamba leads. For control and time-series with small parameter budgets: LNNs win. For efficient sequence modeling with simple deployment: RWKV.
Liquid neural networks research and applications in 2026?
LNN research in 2026 continues at MIT (Hasani’s group), with additional work emerging from autonomous systems labs and robotics groups. Active research areas include scaling LNNs to larger parameter counts (the architecture has not yet matched transformers at billion-parameter scale), applying them to autonomous driving and drone control where parameter efficiency matters, and combining LNN dynamics with transformer attention for hybrid architectures. Commercial deployments remain concentrated in robotics, autonomous vehicles, and edge AI where the small-parameter footprint enables deployment on constrained hardware. Language modeling applications remain limited.
Are liquid neural networks the future of AI?
Probably not as a transformer replacement at LLM scale. LNNs solve a different problem than transformers and excel in different domains. The honest 2026 view: LNNs will continue to win in robotics, autonomous control, time-series prediction on edge hardware, and any application where parameter efficiency and interpretability matter more than raw scale. Transformers and their alternatives (Mamba, RWKV) will continue to dominate language modeling and large-scale generative AI. Research interest in LNN-transformer hybrid architectures is real and may produce useful combinations, but a pure-LNN replacement of transformers at the frontier model scale is not the realistic 2026-2027 trajectory.
What Changed Recently (2026 Update)
Q1 2026: LNN research continues at MIT with extensions to higher-dimensional control tasks. No major commercial LLM deployments using pure LNN architectures.
Q4 2025: Mamba and RWKV continued to scale as the leading transformer alternatives for language modeling. LNNs remained focused on control and time-series applications.
Foundational reference: Hasani et al., “Liquid Time-Constant Networks” (AAAI 2021) is still the canonical paper. For the differential equation formulation and benchmarks, start there.