

Google Won 2025, OpenAI Fumbled, Nvidia Consolidated: The 6 Stories That Defined AI in 2025
Google has the best model, the best distribution, and the best economics. OpenAI has 800 million users and a shrinking moat, and Nvidia's Blackwell concerns.


2025 has been an incredible year, and this chart shows why.
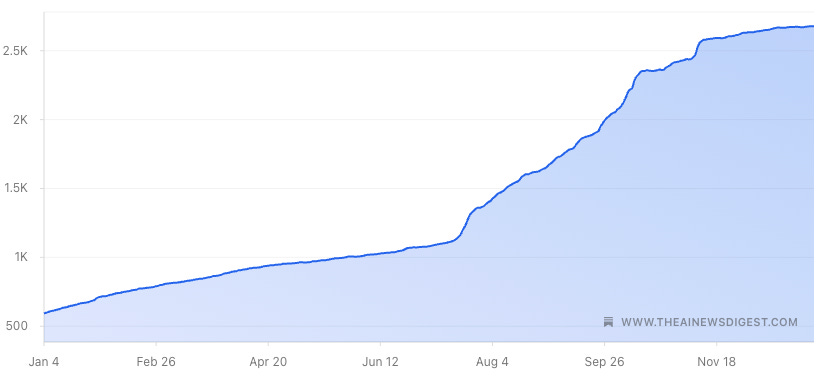
Subscriber growth increased 357% over the past 12 months. That growth is entirely thanks to you sharing this newsletter with others, and I don’t take it for granted. Thank you.
As for the AI industry itself, it’s wild looking back at everything that happened. Some of my predictions held up better…